Architecting for Reliability: How We Scaled Healthcare AI to 45M Requests
In healthcare, "move fast and break things" isn't a strategy—it's a liability. When we built the inference engine for GoApercu, our mandate was clear: deliver the power of Generative AI with the reliability of a pacemaker. Here is the engineering story behind how we achieved 99.94% reliability and 42ms latency at a scale of 45 million requests.
The Core Challenge: Reliability at Scale
Most off-the-shelf LLM wrappers crumble under enterprise load. They struggle with concurrency, lack deterministic outputs, and fail to provide the audit trails required by HIPAA. We couldn't rely on a black box. We needed a custom orchestration engine designed for resilience from the ground up.
Intelligent Routing: The Multi-Model Strategy
We moved away from a "one model fits all" approach. Our orchestration layer acts as a semantic router, analyzing the intent and complexity of every incoming prompt to select the optimal model.
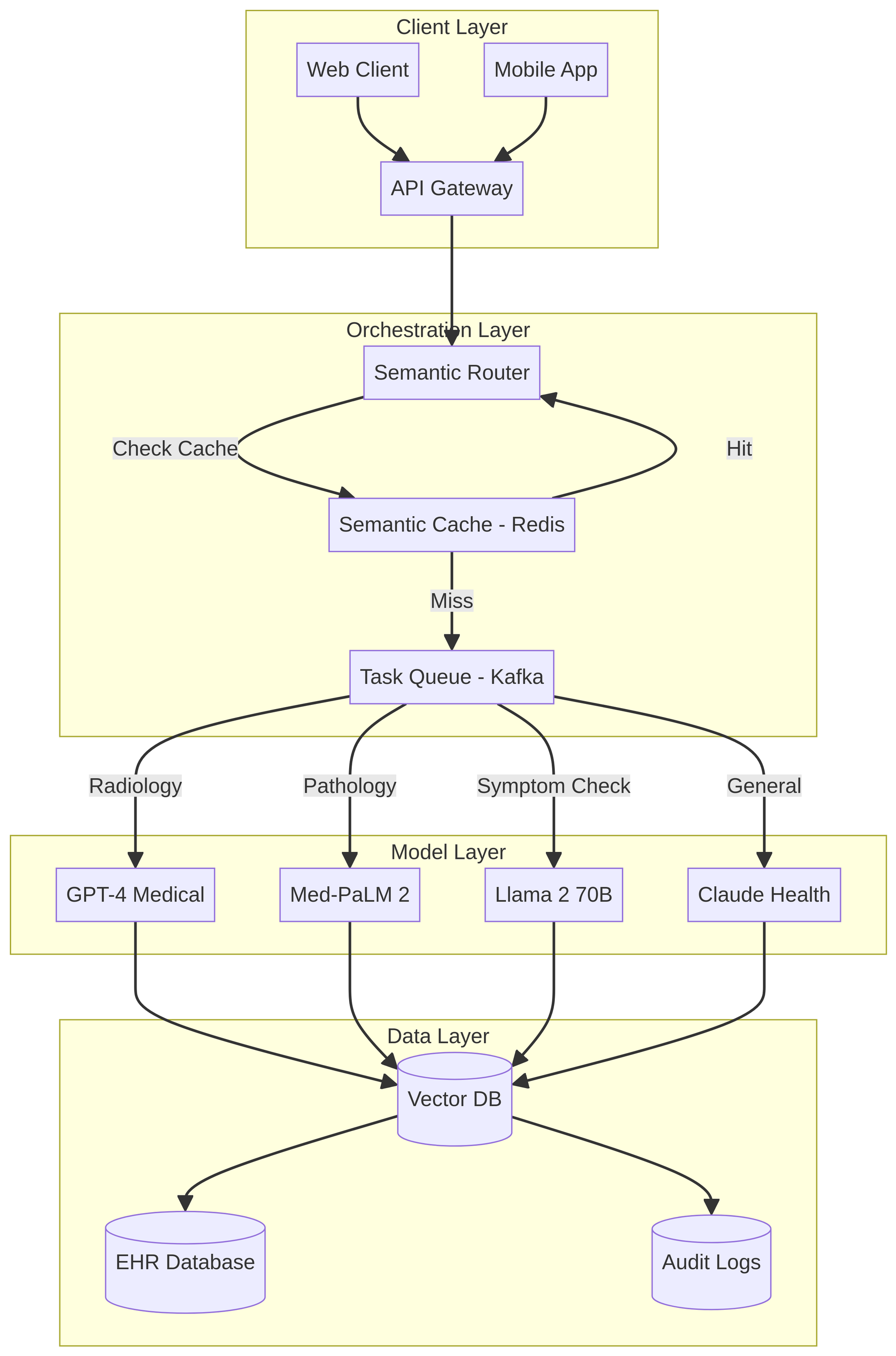
Figure 1: Multi-Model Orchestration Architecture
def route_request(prompt, context):
intent = classifier.predict(prompt)
if intent == "RADIOLOGY_REPORT":
return models.GPT4_MEDICAL(prompt) # 99.7% Accuracy
elif intent == "PATHOLOGY_ANALYSIS":
return models.MED_PALM_2(prompt) # Domain Specialized
elif intent == "SYMPTOM_CHECK":
return models.LLAMA_2_70B(prompt) # Low Latency
else:
return models.CLAUDE_HEALTH(prompt) # General FallbackThis strategy allowed us to achieve 99.7% clinical accuracy in radiology workflows while optimizing costs for simpler tasks.
Optimizing for Speed: The 42ms Benchmark
Latency in clinical decision support can lead to alert fatigue. We optimized our pipeline to hit a 42ms average latency through three key mechanisms:
- Semantic Caching: Using vector databases (Redis/Pinecone) to serve instant responses for semantically identical queries, reducing API calls by 35%.
- Parallel Execution: Spawning concurrent sub-tasks for multi-faceted patient analysis instead of sequential processing.
- Predictive Auto-Scaling: Scaling Kubernetes pods based on token velocity and queue depth rather than just CPU, anticipating load spikes before they impact performance.
Governance as Code
Trust is binary in healthcare. We implemented a strict Governance Middleware that intercepts every request. Before a prompt touches an external gateway, a PII Redaction Service strips sensitive data (names, MRNs) using Named Entity Recognition (NER).
Furthermore, we implemented the Circuit Breaker pattern. If an upstream provider (like OpenAI) experiences increased error rates, our system automatically "trips" the circuit, failing over to backup models or cached responses. This isolation prevented cascading failures during major outages, maintaining our 99.94% success rate.
Conclusion
Building for healthcare requires a shift in mindset from "capability" to "reliability." By treating AI models as commodity components within a robust, governed architecture, we proved that you can scale Generative AI to millions of requests without compromising on safety or speed.